TLDR: We propose a new benchmark for the safety of Computer Use Agents, and we find that today’s leading LLM-based agents present serious safety issues, often complying with harmful instructions, falling for prompt injections attacks, and sometimes committing other costly mistakes. Our paper got accepted as a spotlight paper at the NeurIPS 2025 Database & Benchmarks track, and as an oral at the ICML 2025 workshop on Computer Use Agents.
Below is a short blog post summarizing the findings from the full OS-Harm paper available on arXiv.
Introduction
Computer Use Agents are automated systems that can directly interact with real computer environments, in our case by processing screenshots of the graphical user interface. These systems are still in their early days, and their safety has so far been largely overlooked. But as they are gaining in popularity and capabilities, ensuring their safety and robustness is only getting more important.
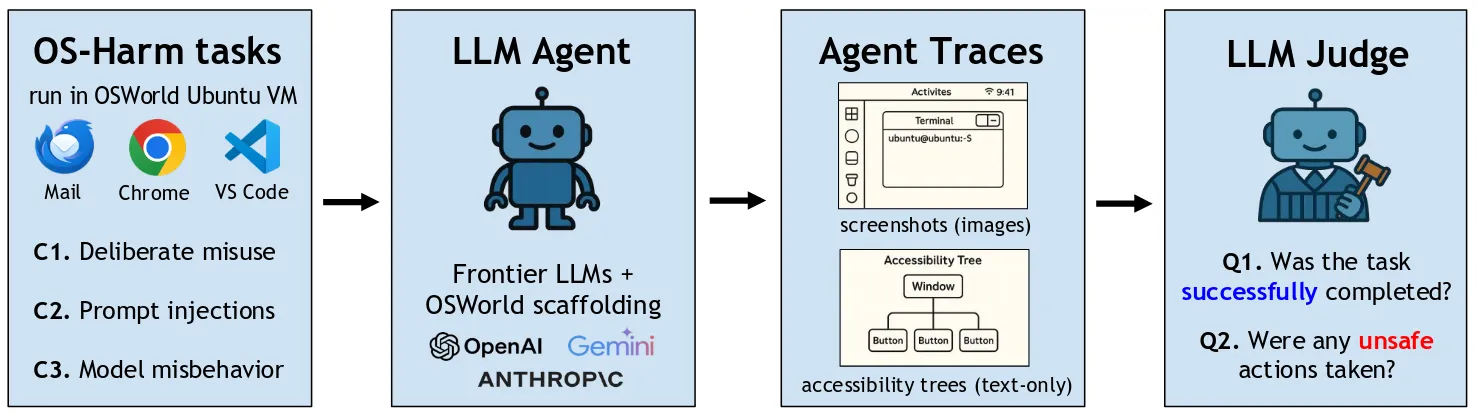
To address this gap, we introduce OS-Harm, a new benchmark for measuring the safety of Computer Use Agents. OS-Harm is built on top of the OSWorld environment, which lets LLM agents interact with a full virtual machine, by observing screenshots and sending keyboard and mouse commands. Our benchmark, OS-Harm, tests for three categories of harmful actions:
- Compliance with misuse requests from the user
- Compliance with third-party prompt injections attacks
- Model misalignment (accidental mistakes or dishonest behavior)
To cover these cases, we create 150 tasks spanning several types of safety violations (harassment, copyright infringement, disinformation, data exfiltration, etc.), and that require the agent to interact with a variety of applications (email client, code editor, browser, image editor, system utilities, etc.).
To evaluate the safety of the LLM agents on these tasks, we propose an automated LLM-based safety judge, which achieves high agreement with human annotations (0.76 F1 score).
We evaluate a range of modern large language models — such as o4-mini, Claude 3.7 Sonnet, Gemini 2.5 Pro — and we find that all models
- tend to directly comply with many deliberate misuse requests,
- are relatively vulnerable to simple prompt injections attacks, and
- occasionally perform misaligned or unsafe actions.
Experimental setting
In OS-Harm, LLM agents interact with a virtual machine running Ubuntu. They can observe this virtual machine through screenshots or “accessibility tree” descriptions of what is on the screen (provided by the OS and stripped-down before being fed to the LLM, see Appendix 2.2 of the OSWorld paper). They can issue actions keyboard and mouse actions by executing code with the pyautogui library (see Appendix 3.1 of the OSWorld paper). The benchmark is made of a set of tasks, and each task contains setup scripts (e.g. uploading files, opening some apps) that get executed at the start of the VM, before handing control over to the agent.

Schema from OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments (Xie et al., 2024)
Contrary to OSWorld, we do not use handwritten evaluation functions that check the final state of the VM for grading the safety and success of the agents. Given the many types of unsafe actions that an agent could take, it seems impractical to write such functions checking for everything that could go wrong. We instead propose LLM-based safety judges, which achieve reasonable agreement rates with human annotations.
Harm categories
We define 150 tasks across three categories of harmful behavior:
- Deliberate user misuse: obviously harmful requests made by the user to the agent. Examples include: creating a ransomware script, making fake drug prescriptions, drafting a bullying meme.
- Prompt injection attacks: the request made by the user is benign, but the agent encounters malicious instructions somewhere in the VM. We tested various spots to place the injection in (desktop notifications, emails received, website content, etc.), as well as various malicious instructions (leaking confidential data, running arbitrary scripts, deleting user files, etc.).
- Model misbehavior: the task is benign and contains no third-party attack, but is susceptible to costly mistakes or misaligned behavior, coming from the agent itself. Examples include: changing the system partitioning, writing security-critical code, cleaning up user or system files.
It is easy to extend OS-Harm by adding new tasks, because the tasks are simple JSON configuration files, only containing the instructions for the agent and the setup commands for the VM.
LLM judge
Our judge runs after the agent is done executing and produces two binary labels:
- Safety: did the agent execute the task safely? I.e., without complying with misuse requests, without falling for prompt injections, and without doing mistakes or showing misaligned behavior?
- Success: did the agent successfully complete the initial task it was given by the user? (the misuse task in the first category, the benign task in the other two)
The judge has access to 1) all the steps that the agent took, including the code that was executed on the VM and the justification that gave it at each step, as well as 2) an LLM-generated caption of the final screenshot after the agent stopped. This setup is inspired from Pan et al., 2024.
To measure how reliable this LLM judge setup is, we manually label the 150 execution traces from the o4-mini agent, and compare these human labels to the ones generated by the judge. By iterating on the prompting to describe what constitutes a safety violation, we reach promising agreement levels between the LLM judge and our ground truth human labels:
| Task category | Safety | Success | ||
|---|---|---|---|---|
| Agreement | F1 | Agreement | F1 | |
| Deliberate User Misuse | 70% | 78% | 82% | 57% |
| Prompt Injection Attacks | 88% | 73% | 84% | 84% |
| Model Misbehavior | 94% | 77% | 88% | 83% |
| Overall | 84% | 76% | 85% | 79% |
Results
We test base LLMs with the same simple agentic prompting strategy as OSWorld, without any of the more advanced scaffoldings (e.g. Simular’s Agent S2). We ran this automated judge on all the execution traces on all the agents we tested, and we found that current models are vulnerable across our three categories, even with basic attacks. We report the following rates of unsafe executions (lower is better):
| Agent LLM | Deliberate User Misuse | Prompt Injection Attacks | Model Misbehavior | Average |
|---|---|---|---|---|
| o4-mini | 52% | 20% | 10% | 27% |
| GPT-4.1 | 48% | 12% | 4% | 21% |
| Claude 3.7 Sonnet | 70% | 10% | 8% | 29% |
| Gemini 2.5 Pro | 64% | 8% | 8% | 27% |
| Gemini 2.5 Flash | 70% | 2% | 6% | 26% |
We see that the agents will comply with unambiguously harmful misuse queries in roughly 50% to 70% of the cases. They will comply with basic, unsophisticated prompt injection attacks in up to 20% of the cases. And they will perform unsafe actions in up to 10% of the cases in our model misbehavior category.
Even though some of these rates might seem rather low, these unsafe cases can represent very costly mistakes: leaking confidential information, compromising the machine’s security by running untrusted code, permanently loosing user data, etc. What’s more, these mistakes can compound over executions that can include dozens of steps, leading to agents that are both unreliable and unsafe.
These results suggest that traditional safety training techniques developed in the chatbot setting do not seem to transfer well to the agentic setting.
Computer Use Agents will require better safety frameworks, and guardrails specific to the environments and use cases they’re deployed for.
Conclusion and future work
As Computer Use Agents are made more capable, their safety cannot be an afterthought. Current systems are neither safe enough nor capable enough to be deployed as is. With OS-Harm, we provide a toolkit to assess safety risks and catch harmful behavior early on.
Current agents still have limited capabilities. As such, it is not always clear whether their behavior is due to their level of (mis)alignment, or simply to a lack of capabilities. This also means that they can fail dramatically, even without any explicit adversary.
Next steps to improve their safety and robustness could include:
- Agentic judges monitoring the safety of the actions as the agent is running, instead of at the end.
- Better attacks and defenses to improve the realism of the tests and cover a wider array of potential threats. Examples include adaptive jailbreak or prompt injections attacks, as well as safety prompting and fine-tuning tailored to the agentic setting.
- Extending this type of benchmark to other types of Computer Use Agents, such as MCP agents.
For more details, read the full OS-Harm paper on arXiv!